Tabulated Weak Rate Sources#
There are a variety of sources for tabulated weak rates. Each of these sources has their own class that will just read in that source:
FFNLibrary: from Fuller et al. [1982] covering \(21 \le A \le 60\)OdaLibrary: from Oda et al. [1994] covering \(17 \le A \le 39\)LangankeLibrary: from Langanke and Martínez-Pinedo [2001] covering \(45 \le A \le 65\)PruetFullerLibraryfrom Pruet and Fuller [2003] covering \(65 \le A \le 80\)SuzukiLibrary: from Suzuki et al. [2016] covering \(17 \le A \le 28\)
Additionally, a union of these sources can be read in via TabularLibrary. However, since there is some overlap in the
coverage between these different sources, we need to pick an order of precedence. The default order is the sequence in the
list above. However, this can be overridden by via the ordering keyword argument.
import pynucastro as pyna
Read in the weak rates. We’ll use the default ordering, but we’ll explicitly specify it here:
tl = pyna.TabularLibrary(ordering=["ffn", "oda", "pruet_fuller", "langanke", "suzuki"])
Important
ordering specifies the sources from lowest to highest precedence. In the above example, we first read in the ffn rates,
then the oda rates, and replace any ffn rates with oda rates if they represent the same nucleus and process.
The we do the same with the langanke and the suzuki rates.
The default ordering, overwrite the repeated rates accordingly to the year of publication of each one of these sources, keeping the newest ones and discarding the oldest ones.
rates = tl.get_rates()
Now let’s make a plot that shows the source for each rate, colored by the reactant.
We’ll plot in terms of \((Z, N)\), so let’s find the bounds of the rate coverage, and round it to the nearest 5
high_Z = max(r.products[0].Z for r in rates)
high_N = max(r.products[0].N for r in rates)
max_size = 5 * (max(high_Z, high_N) // 5 + 1)
We’ll use the filename to sort the rates by source:
ffn_rates = [r for r in rates if r.rfile_name.startswith("ffn")]
suzuki_rates = [r for r in rates if r.rfile_name.startswith("suzuki")]
pruet_rates = [r for r in rates if r.rfile_name.startswith("pruet")]
langanke_rates = [r for r in rates if r.rfile_name.startswith("langanke")]
oda_rates = [r for r in rates if r.rfile_name.startswith("oda")]
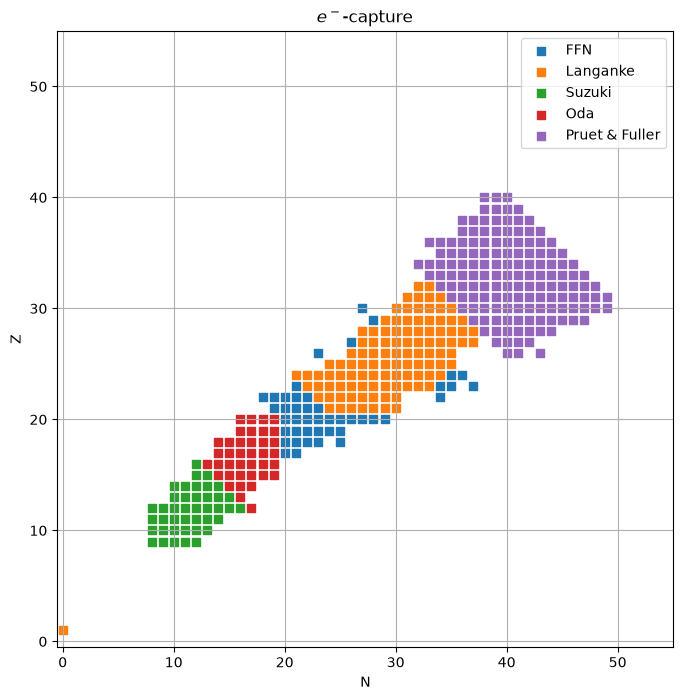
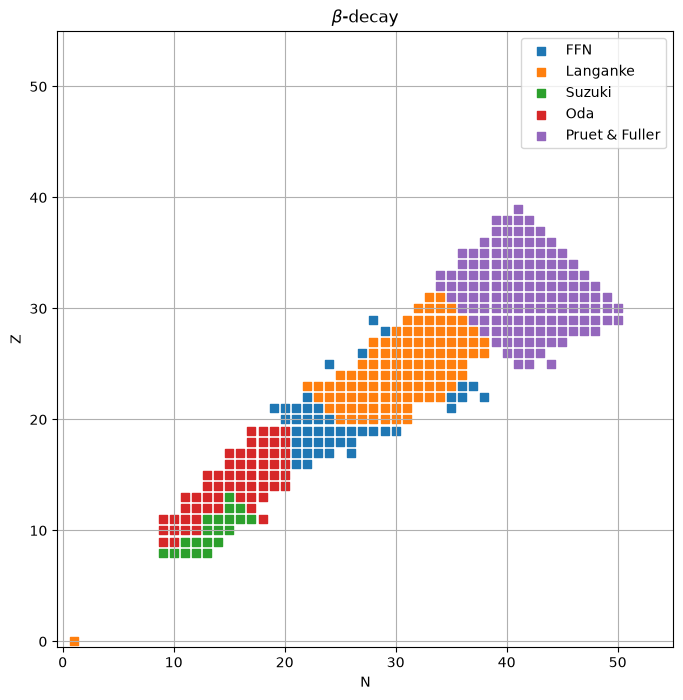
Finally, plot them on a grid, separately showing the \(\beta\)-decay and \(e^-\)-capture.
\(\beta\)-decay rates#
import matplotlib.pyplot as plt
fig, ax = plt.subplots()
ax.scatter([r.reactants[0].N for r in ffn_rates if r.weak_type.startswith("beta")],
[r.reactants[0].Z for r in ffn_rates if r.weak_type.startswith("beta")],
marker="s", color="C0", label="FFN")
ax.scatter([r.reactants[0].N for r in langanke_rates if r.weak_type.startswith("beta")],
[r.reactants[0].Z for r in langanke_rates if r.weak_type.startswith("beta")],
marker="s", color="C1", label="Langanke")
ax.scatter([r.reactants[0].N for r in suzuki_rates if r.weak_type.startswith("beta")],
[r.reactants[0].Z for r in suzuki_rates if r.weak_type.startswith("beta")],
marker="s", color="C2", label="Suzuki")
ax.scatter([r.reactants[0].N for r in oda_rates if r.weak_type.startswith("beta")],
[r.reactants[0].Z for r in oda_rates if r.weak_type.startswith("beta")],
marker="s", color="C3", label="Oda")
ax.scatter([r.reactants[0].N for r in pruet_rates if r.weak_type.startswith("beta")],
[r.reactants[0].Z for r in pruet_rates if r.weak_type.startswith("beta")],
marker="s", color="C4", label="Pruet & Fuller")
ax.legend()
ax.set_xlabel("N")
ax.set_ylabel("Z")
ax.set_xlim(-0.5, max_size)
ax.set_ylim(-0.5, max_size)
ax.set_aspect("equal")
ax.grid()
ax.set_title(r"$\beta$-decay")
fig.set_size_inches(8, 8)
\(e^-\)-capture rates#
fig, ax = plt.subplots()
ax.scatter([r.reactants[0].N for r in ffn_rates if r.weak_type.startswith("electron")],
[r.reactants[0].Z for r in ffn_rates if r.weak_type.startswith("electron")],
marker="s", color="C0", label="FFN")
ax.scatter([r.reactants[0].N for r in langanke_rates if r.weak_type.startswith("electron")],
[r.reactants[0].Z for r in langanke_rates if r.weak_type.startswith("electron")],
marker="s", color="C1", label="Langanke")
ax.scatter([r.reactants[0].N for r in suzuki_rates if r.weak_type.startswith("electron")],
[r.reactants[0].Z for r in suzuki_rates if r.weak_type.startswith("electron")],
marker="s", color="C2", label="Suzuki")
ax.scatter([r.reactants[0].N for r in oda_rates if r.weak_type.startswith("electron")],
[r.reactants[0].Z for r in oda_rates if r.weak_type.startswith("electron")],
marker="s", color="C3", label="Oda")
ax.scatter([r.reactants[0].N for r in pruet_rates if r.weak_type.startswith("electron")],
[r.reactants[0].Z for r in pruet_rates if r.weak_type.startswith("electron")],
marker="s", color="C4", label="Pruet & Fuller")
ax.legend()
ax.set_xlabel("N")
ax.set_ylabel("Z")
ax.set_xlim(-0.5, max_size)
ax.set_ylim(-0.5, max_size)
ax.set_aspect("equal")
ax.grid()
ax.set_title(r"$e^-$-capture")
fig.set_size_inches(8, 8)